
Cricket Matches Prediction using Data Science
Objective
To predict the outcome of the cricket match result using data science based on the historical and current data.
Project Overview
In recent times, data science predictive modeling plays a crucial role in the sports. Cricket is one of the famous sports in India. On the given day, any team can win the match with its performance. This makes the challenge in predicting the accurate outcome of the cricket match.
The cricket game involves 3 formats – namely, Test Matches, ODIs andT20s. This project concentrates on the latest format of the game T20. To predict the result of the T20 game, we analyze the type of ground, teams past performance, batting and bowling potentials of the 11 players of both teams using their past performance. Another important parameter considered for prediction is toss decision factor.
Proposed System
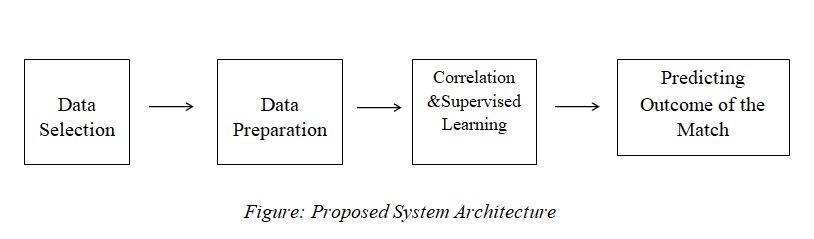
With the advanced technology in today’s world, we are in need of predicting the outcome of the match. This paper focuses on predicting the outcome of the T20 matches. Supervised learning algorithms are used to predict the outcome of the match. The proposed system architecture is shown in the figure.
Cricket Matches Prediction Modules
Module 1:Data Selection
The required data is collected from the cricket website. The data should consist of player details with all features.
Batting records
- Runs scored
- Strike rate
- Batting average
- Highest score
- Home/ Away
- Opposite team
Bowling records
- Balls bowled
- Wickets taken
- Economy rate
- Best bowling
- Number of 4 wickets haul
- Home/ Away
- Opposite team
Module 2: Data Preparation
Data preparation is an important step in any data science project. It consists of data cleaning, integration, normalization, transformation, reduction, feature extraction, and selection, etc.
Module 3: Correlation
In a T20 match, toss is the crucial factor in deciding the outcome of the match. Most of the toss-winning the captain choose to field first. It’s because of the perception is that, the team fielding first winning the most matches in the T20 match. To identify this relation, correlation techniques are used. Here, the correlation between toss winner and match winners is analyzed.
Module 3 : Implementation of Supervised Learning
The required supervised learning algorithm is applied to the given data set. This algorithm is applied to the data set to analyze the player performance and the accuracy is calculated. The interesting relationships between the player performances are identified using association rules. Predictive analytical techniques are used to predict the outcome of the T20 match using previous historical data and current data.
Module 4 : Predicting the Outcome of the Match
Prediction is a data mining function that discovers the future behaviors. Using the predictive analytics method, the outcome of the cricket match is predicted. Here, supervised learning approach is used.
Software Requirements
- Weka 3.8
- Netbeans
- SQL Server
Hardware Requirements
- Hard Disk – 1 TB or Above
- RAM required – 4 GB or Above
- Processor – Core i3 or Above