
Facebook Data Analysis Using Hadoop
Objective
To analyze the Facebook data using Hadoop for the purpose of better decision making in the business.
Project Overview
Smart phone without social media usage in daily lifestyle of people is unthinkable. That much effect has been created in the lifestyle of people by smartphone and social media. There are many social media such as Facebook, Twitter, etc., As per 2017 statistics, nearly 1.37 billion daily active users for Facebook. Every user contributes some type of data to in structured or semi-structured or unstructured data format. Business owners utilize this data to understand customer need and their behavior to make profit in their business. Facebook data analysis is the process of collecting, analyzing Facebook data and visualizing extracted results to the end user.
The user data is collected from Facebook based on their activities. User behavior, number of likes, number of posts, type of posts, their comments, etc. are stored by the database server. Comments by the user in unstructured formats, while other data in structured and semi-structured format. Petabytes of data is generated by Facebook users. So Hadoop, MapReduce and related big data concepts used in this project to analyze the data.
Proposed System
The proposed system focuses on analyzing sentiments of Facebook users using Hadoop. The user sentiments collected are categorized into positive, negative, neutral.The proposed system architecture is shown in the figure.
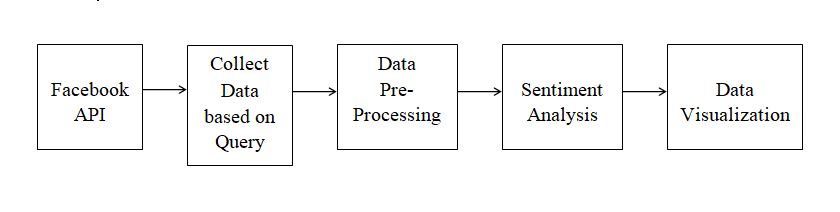
Figure: Proposed System Architecture
Module 1: Facebook API
Facebook API is used as an authentication API to extract the user contents related to the query requested.
Module 2: Data Pre-Processing
Data Collection: The data are collected from Facebook using Hadoop through the Facebook API based on the requested query.
Data Preparation: The collected data consists of different emotions, stop words, acronyms, etc. But during analysis this type of data needs to be converted into the proper format to extract sentiments from the user behavior.
- Tokenization
- Various Dictionaries
- Acronym Dictionary
- Stop Words Dictionary
- Emoticon
Consider one of the Facebook posts regarding new mobile features. Users opinion about the new phone might be positive or negative or neutral.
Example for Positive Sentiment
Looks are awesome.Battery backup is excellent. Camera is good.The display light quality is good.
Example for Neutral Sentiment
Although this is good mobile, looks good, but Problem is that it doesn’t provide separate Space for dual SIM & memory card together.
Example for Negative Sentiment
Not good one as expected. Camera quality very poor.
Tokenization
Comments extracted from Facebook are divided into tokens. This is known as tokenization process. For example, ‘Looks are awesome. Battery backup is excellent. Camera is good. The display light quality is good.’is divided down into ‘Looks’, ‘are’, ‘awesome’, ‘.’, ‘Battery’, ‘backup’, ‘is’, ‘excellent’, ‘.’, ‘Camera’, ‘is’, ‘good’, ‘.’, ‘The’, ‘display’, ‘light’, ‘quality’, ‘is’, ‘good’, ‘.’
Acronym Dictionary: It is used to give the required acronym for the words, if needed.
Stop Words Dictionary: It is used to remove the unrelated words in the sentiment analysis process. Example: A, An, The, Has, Are, Is.
Emoticon:This is used to detect the emoticons for the purpose of classifying the comment as positive or negative or neutral.
Module 3: Sentiment Analysis
The user sentiments collected from the Facebook are categorized into positive, negative, neutral. This sentiment analysis can be performed for different purposes based on the business objectives.
Module 4: Data Visualization
After the Facebook sentiment analysis, the extracted and analyzed sentiments are visualized using Tableau.
Software Requirements
- Linux OS
- Hadoop & MapReduce
- Facebook API
- HIVE
- Tableau
Hardware Requirements
- Hard Disk – 1 TB or Above
- RAM required – 4 GB or Above
- Processor – Core i3 or Above
Technology Used
- Big Data – Hadoop

Leave a Reply