
Objective
- To analyze the Aadhar data using Hadoop to extract meaningful knowledge for the purpose of better decision-making by the central and state government.
Project Overview
The worlds largest democracy, India is the second largest nation in terms of population, with 1.3 billion population. Among these, 99% of adult population enrolled for Aadhar, the unique identity provided by the Government of India for diverse purposes. The government maintains the Aadhar related data in digital format. https://data.uidai.gov.in/uiddatacatalog/dataCatalogHome.do website provides the access to Aadhar card related data set. The Public can access some of the sources of these data and they can analyze to extract useful information and generate reports.
The data set covers more than 99% adult population of our nation. So the amount of data generated by Aadhar is very huge. Similarly, all the data collected for this unique identity is not in structured data. It also consists of unstructured and semi-structured data. Also, the enrollment is still in the process. The processing speed of this data generation is high. Therefore, theses characteristics come under the big data concept.
The purpose of Hadoop is storing and processing large amount of the data. So this project uses the Hadoop for processing Aadhar data. The input data is processed using MapReduce and then result is loaded into Hadoop Distributed File System (HDFS). Finalreports generated using Tableau (Business Intelligence Software).
Proposed System
The proposed system concentrates on analyzing Aadhar related data using Hadoop for the purpose of better decision making by the Government of India. The proposed system architecture is shown in the figure.
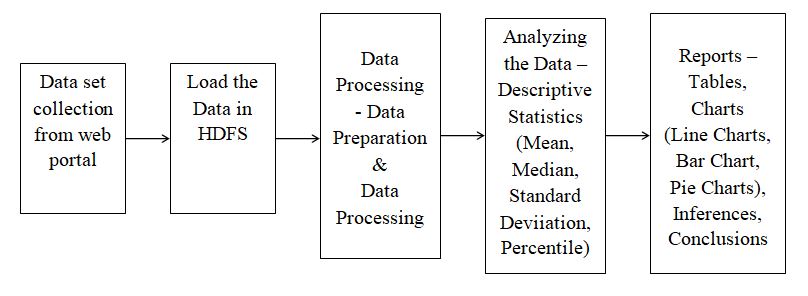
Step 1: Data Preparation
Data Selection: The required data set is collected from the government web portal.
Data Loading: The collected data set loaded into Hadoop Distributed File System environment.
Data Pre processing: The collected data set might consist of missing values and noisy data. If analysis is performed on this data, it may lead to wrong results. So to avoid this, data pre processing is done on the data set.
Step 2: Data Analysis
Data Analysis: Now the collected data set is ready for data analysis. Descriptive statistics like mean, median, mode, percentile are applied.
Step 3: Results
Report Generation: After the data analysis, the analyzed results need to be visualized. Tableau can be used for this purpose. Bar charts, Line charts and Pie charts are generated along with the table format.
Statistics Questions
- Identify the total number of cards approved by gender wise
- Identify the total number of cards approved by state wise
- Identify the total number of cards approved by age wise
- Identify the total number of cards approved in rural areas
- Identify the total number of cards approved in rural areas
- Identify the total number of cards approved in city areas
- Identify the number cards rejected by government (State wise)
- Identify the number cards rejected by government (Gender wise)
- Identify the number cards rejected by government (Age wise)
Advantages
- Government can immediately take corrective measures for the issues found in the Aadhar card related data analysis.
- Central and state government can take necessary precaution measurements to avoid the issues in future.
Software Requirements
- Linux OS
- MySQL
- Hadoop&MapReduce
- Tableau
Hardware Requirements
- Hard Disk – 1 TB or Above
- RAM required – 8 GB or Above
- Processor – Core i3 or Above
Technology Used
- Big Data – Hadoop
- Statistics

Leave a Reply