Wiki Page Ranking With Hadoop
Objective
To ranking the given wiki pages using Hadoop.
Project Overview
One of the biggest changes in this decade is the availability of efficient and accurate information on the web. Google is the largest search engine in this world owned by Google, Inc. The heart of the search engine is PageRank, the algorithm for ranking the web pages developed by Larry Page and Sergey Brin at Stanford University. Page Rank algorithm does not rank the whole website, but it’s determined for each page individually.
The page ranking is not a completely new concept in the internet search. But it’s becoming more important nowadays, to improve the web page ranking position in the search engine. Wikipedia has more than 3 million articles as of now and still its increasing everyday. Every article has links to many other articles. This is the significant factor in page ranking. Each article has incoming and outgoing links. So analyzing which page is the most important page than the other pages is the key. Page ranking does this and rank the pages based on its importance.
Proposed System
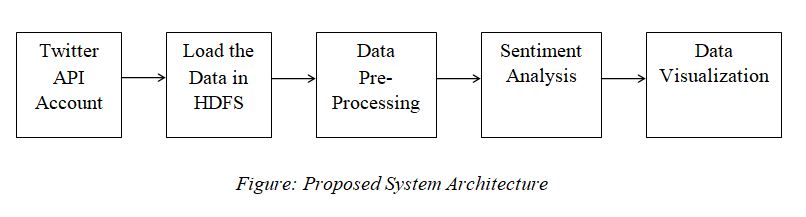
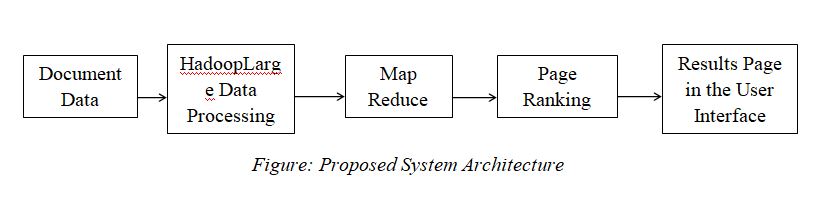
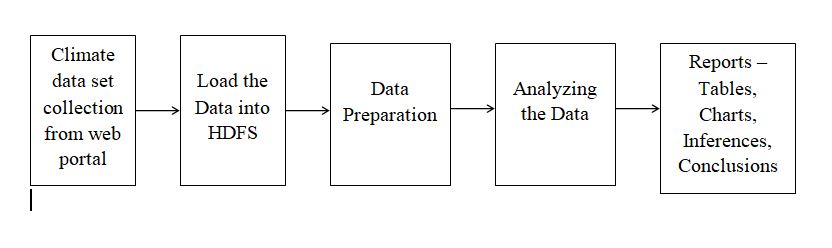
The proposed Wiki Page Ranking With Hadoop project system focuses on creating best page ranking algorithm for Wikipedia articles using Hadoop. The proposed system architecture is shown in the figure.

All the document data in the database are indexed. The web search engine searches the keyword in the indexing of the database.Then to search the information in the database, the web crawler is used. After finding the pages, the search engine shows the top web pages that are related to the query.
MapReduce consists of several iterative set of functions to perform the set of search results. Map() function gathers the query results from the search and reduce() function performs the add operation. The wiki page ranking project using Hadoop involves 3 important Hadoop steps.
- Parsing
- Calculating
- Ordering
Parsing
In the parsing step, wiki xml is parsed into articles in Hadoop Job. During the mapping phase, get the name of the article and outgoing link connections are mapped. In the reduce phase, get the links to other pages.Then store the page, early rank and outgoing links.
Map(): Article name, outgoing link
Reduce(): Link to other pages
Store: Page, Rank, Outgoing link
Calculating
In the calculating step, the Hadoop job will calculate the new rank for the web pages.In the mapping phase, each outgoing link to the page with its rank and total outgoing links are mapped using map function.In the reduce phase, calculate the new page rank for the pages.Then store the page, new rank and outgoing links.Repeat these processes iterative to get the best results.
Map(): Rank, outgoing link
Reduce(): Page rank
Store: Page, Rank, Outgoing link
Ordering
Here the job function will map the identified page. Then store the rank and page. Now we can see top n pages in the web search.
Wiki Page Ranking With Hadoop Benefits
- Fast and accurate web page results
- Less time consuming
Software Requirements
- Linux OS
- MySQL
- Hadoop & MapReduce
Hardware Requirements
- Hard Disk – 1 TB or Above
- RAM required – 8 GB or Above
- Processor – Core i3 or Above
Technology Used
- Big Data – Hadoop